Synchronous replication is dead, long live synchronous replication.
Posted on February 3, 2012 by TheStorageChap in Data Center, Replication, VPLEXI had the pleasure of spending time at Cisco Live Europe (#CLEUR) this week talking about all things related to active/active and active/passive replication. We had a packed booth demonstrating and talking about how we could use, amongst other things, EMC VPLEX in conjunction with VCE Vblock solutions to enable the distributed datacentre. What was interesting about Cisco Live, is that the attendees are not our normal day to day storage or application focused audience so it was interesting to get the views of people on the other side of the IT fence. What is clear is that the distributed datacentre message is really resonating with everyone and I was encouraged to the point that I believe we should all make this the value proposition of VPLEX, something I have been doing since the start of the year.
Many of the people I spoke with already had synchronous replication between their datacentres and I had the same two questions asked on several occasions.
Why is this different to the synchronous replication I am already doing?
Firstly, VPLEX is array independent and supports fibre channel block storage from a large proportion of the major vendors on the market today. This is important as it frees up the resources on the array to handle application I/O, but it also takes all of the complexity out of managing replication in a heterogeneous environment and having to match storage vendors across sites.
Secondly, an array based, synchronous or asynchronous, replication solution operates an active/passive model; the primary copy of the data is available for application I/O but the off-site copy is offline and only invoked in the event that you have a problem at the primary site. From an asset point of view this leads to inefficient utilisation of the storage and compute assets available across the data centres. The VPLEX architecture specifically enables the utilisation of the storage and compute assets across both datacentres. The I/O for a single distributed virtual volume can be served from the storage arrays at both sites. What is a distributed virtual volume? “Simply” a virtual volume, with the same identifiers, that is accessible across both sites and that is consistently synchronously mirrored between physical storage arrays in each of those sites by VPLEX.
Let me give you an example. Today customers run VMware HA clusters within a datacentre. VMware HA like all clustering technologies works because you have multiple nodes sharing the same LUN which is actively presented from a single array. This LUN may be mirrored by the storage to another target site, but all of the I/O for all of the VMs that are part of that cluster is going to one storage array. Using VPLEX Metro you can take those same source and target LUNs and encapsulate them within VPLEX. You switch off the array replication and instead create a distributed virtual volume, effectively a RAID 1 mirror between those two LUNs using VPLEX. Let’s assume that there were four VMs and corresponding VMDKs running on that LUN in the source site. Having now distributed that LUN to the remote site, I can non-disruptively move two of those VMs to ESX nodes attached to the same distributed virtual volume in the target site. Whilst they are running in the target site the I/O is provided by the ESX servers and storage array in the target site. Another benefit is that unlike the storage array based solution if the storage array in either site has a failure, there is no need to failover the applications to the other site; with VPLEX everything continues running for all four VMs.
So contrary to some beliefs, synchronous replication per se, is not dead, however how and where that synchronous replication occurs and how it is implemented is rapidly changing in support of the true distributed datacentre.
Do I have to merge my fibre channel fabrics to make this work?
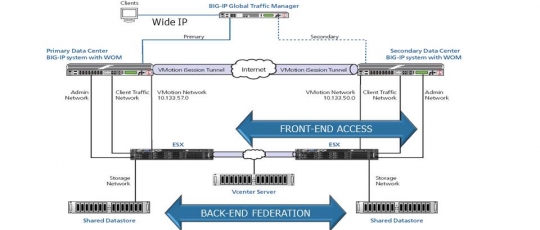
Not if you don’t want to. The communication to enable the distributed virtual volume architecture is between the VPLEX clusters which can be connected over 10GigE or a separate Fibre Channel network. The two main considerations are actually application failover between sites and client access across the distributed datacentres.
When you investigate clustering applications across nodes, that are now distributed across datacentres, the primary requirement is that all nodes are on the same IP subnets. For some customers this is simply a case of stretching their subnets across the datacentres, for other customers this means deploying technologies like Cisco OTV. The main advantage of Cisco OTV is that it can extend the Layer 2 domains across geographically distant datacentres by providing built-in filtering capabilities to localise the most common networking protocols (Spanning Tree Protocol, VLAN Trucking Protocol [VTP], and Hot Standby Router Protocol [HSRP]) and prevent them from traversing the overlay, therefore keeping protocol failures from propagating across sites; something that simply stretching the subnet would not achieve.
If you have taken the trouble to construct an application environment that remains available when you lose a datacentre you of course need to make sure that users requests are directed to the closest and best performing datacentre that is available. This requires global load balancing solutions such as the technologies like Cisco Global Site Selector which can redirect users to the most appropriate site dependent upon specific disaster recovery policies.

EDIT 25/10/2012 or alternative such as those from F5

Discussion · 2 Comments
There are 2 responses to "Synchronous replication is dead, long live synchronous replication.".Leave a Comment